Navigating the Manifold
Toward a theory of human creative processes in the age of AI
Software engineering and music composition are very different processes—reconciling them to draw meaningful analogy requires abstraction to the point of pedantry. Nonetheless, I think it leads to some interesting results. So let’s go there.
320 million bits
To simplify the case, let’s assume the output of both processes is a single digital file. This omits many significant aspects of the job—in software: deployment of distributed systems, in composing: live performance, distribution, and marketing—but for now let’s just focus on the process of creating a single executable or audio master. To make it easier, let’s say that in both cases this is a binary file of size 40 MB (320 million bits).
One way to conceptualize this artifact is as a single point in a 320,000,000-dimensional binary space (“binary” as in each dimension has two discrete values, 0 and 1). Equivalently, the artifact can be seen as a specific corner of this 320,000,000-dimensional unit hypercube.

Never Gonna Give You Up is a corner of the hypercube
Under this somewhat absurd conceptualization, the process of programming or composing can be construed as specifying the desired corner of this hypercube. Whether that specification is a function of problem-solving or creative expression is the biggest difference between the two tasks under comparison, but is relatively inconsequential to the following reasoning. In either case, doing so directly is clearly an absurd proposition—it would be akin to writing a program or song by manually specifying every 0 and 1 of the binary file.
The first obvious observation is that not every corner of this unit hypercube is a valid program or song. For one, only a subset of points represents files readable or executable on a given chip architecture, or files interpretable as the .wav format. And even among the subset of corners that are valid .wav files, the vast majority of these will sound to a human like random noise; only a very small subset of these corners could plausibly be called “music” (though the precise boundaries here are fuzzy—spend a year at a Composition & Experimental Sound Practices MFA program and you’ll see what I mean).
Latent Space
Enter the idea of “latent space.” For the uninitiated, a latent space is a low-dimensional representation of some data distribution such that similar items are closer together. In machine learning models, these “latents” can be intermediate representations as part of a generative process, or used directly for downstream tasks like quantifying the semantic similarity of two pieces of data. (Researchers: forgive me for my definitional approximations here).
The beauty of a good latent space is that it can be highly semantic—geometric relationships in the space can map nicely to conceptual relationships. To quote the most famous example from Mikolov et al (2013), in the latent space of a machine-learned language model, the distance and direction between “king” and “queen” is equivalent to that of “man” and “woman.” (In practice, this correspondence between “concept” and latent dimension is far less pure than one might hope, though there is promising progress on understanding this through Anthropic’s recent work on Superposition.)
Conceptually, one can imagine some “ideal latent space” where every dimension purely maps to a meaningful concept in the domain (perhaps “key,” “tempo,” or “intensity;” or “architecture,” “code style,” or “performance characteristics”). This property is known as “monosemanticity,” and such a latent space would be perfectly disentangled. One can also imagine some ideal generative model, which is a function that takes a coordinate in the ideal latent space and maps it to a precise corner of the unit hypercube. It’s in serious doubt whether such a perfectly disentangled latent space could truly exist (Locatello et. al, 2019), but for the purposes of this description it represents a meaningful ideal.
Manifold Theory
As sometimes happens, I got about this far in the reasoning process on my own before excitedly explaining this new thinking to some researcher friends, one of whom gently informed me that this is already a well-understood line of thought in deep learning known as “manifold theory.” Manifold theory, when put in the foregoing terms, is the idea that we can create a model that defines a “manifold” on the 320,000,000-dimensional space which represents the aforementioned subset of all plausible programs or songs. Under this definition, the ideal latent space is a space that maps to a manifold, and has the property of monosemanticity.
Abstraction
Now, let’s broadly define an “abstraction” as a space of some dimensionality that, similar to the ideal latent space, maps to the manifold. Unlike the ideal latent space, a single point in a given abstraction-space may map to a region of the manifold, or some subset of the points defined by the manifold (rather than perfectly mapping to a single point). From this perspective, the ideal latent space is a specific case of an abstraction over a given manifold, that is by definition complete and maximally semantic, whereas the general case of an abstraction could be any mapping. This is a purposefully loose definition—bear with me.
The reason I set aside this loose definition of “abstraction over the manifold” is that we can use it to understand machine-learned creative tools in the same terms as “traditional” tools. That is: all modern creation tools, from Logic Pro to VSCode to MIDI and samplers to programming languages and compilers can be seen as abstractions over their respective manifolds. These tools give us useful, very limited, very explicitly defined abstractions with which to navigate the manifold. Usually, these abstractions have a highly (or completely) deterministic relationship between the abstract representation (say, a midi file and a set of sampler instruments, or source code and a compiler) and the resulting point on the manifold (the resulting .wav file or executable), but are far from monosemantic. That is, they require a highly-trained human to map some semantic specification of the desired output to its representation in these abstractions. Often, we use multiple such abstractions in conjunction to create the desired output.
In these terms, the act of creation is the act of using some combination of abstractions to navigate to a desired point on the manifold. In practical terms, this is a time-based process that starts with the conceptualization of a goal, and proceeds with the progressive refining of the desired subset of the manifold, until the goal is achieved. The imagined “perfect” generative AI would be a generative model whose interface is an ideal latent space—an untrained user could “program” a song or piece of software using perfectly semantic abstraction, going through the entire refinement process using only semantic controls, without any need for non-semantic technicalities like semiquavers or ternary operators.
Cursor vs. Suno
If the creative process is the process of narrowing an aperture on a desired point on the manifold, the current implementation of machine-learned systems is where the two example fields diverge.
One of the state-of-the-art software generation tools at the time of writing is Cursor. It’s an IDE—a fork of VSCode—with LLM-based code generation woven in in increasingly intricate ways. First it could generate a few lines of code, then it could generate whole files, then it could coordinate code changes across files. The latest features allow multiple “agents” to edit and test changes across the codebase simultaneously.
On the music side, the most state-of-the-art music generation platform at the time of writing is Suno. It’s a music generation product that takes a text prompt (style and lyrics) and optional reference audio and generates 1–3 minutes of audio.
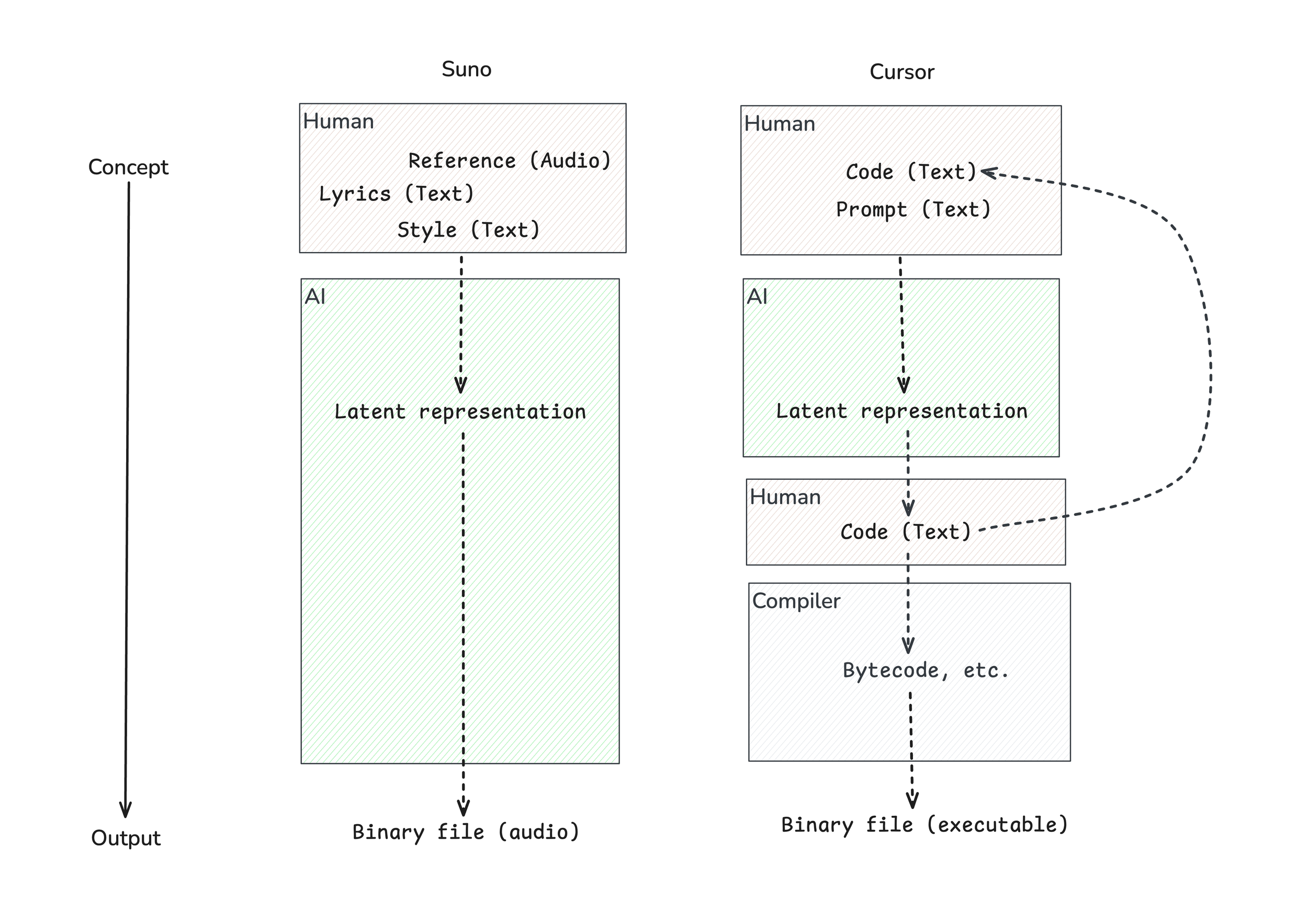
Suno and Cursor compared in terms of a Human vs. AI control in a professional workflow
When put in terms of different types of abstractions, the difference between these workflows couldn’t be more clear. Cursor inserts itself in the middle of the existing professional workflow, accelerating an increasingly large portion of the process, but always giving a human control of the last abstractions, and allowing iteration. Suno, on the other hand allows the human to guide the initial heading of the aperture-narrowing, but then puts the vast majority of the process, and, crucially, the final steps, in the hands of the AI.
In many ways, I’ve set up a false equivalency here. That’s a fair criticism. Cursor is clearly a professional tool, while Suno is clearly a consumer product (see my discussion of the distinction here). The two companies have very different economics governing their product positioning. However, given we now have a language to compare these two, it’s worth exploring why this equivalency is false. In other words: where is the Suno for software, and where is the Cursor for music?
Suno for Software
While there are many platforms attempting this (Replit Agents come to mind), none has captured the market yet. I think the reasoning is clear: giving the AI control of the bottom half of the creation pipeline only works when the AI has solved the last-mile problem. In systems where this isn’t the case, the result doesn’t work. In software, it’s very obvious when an output doesn’t work! Not so much so in music.
I would assert that Suno’s outputs don’t quite work as music, and though with each model they get closer to representing some subset of the manifold (that is, creating plausible music), their current paradigm will never give the iterative control necessary for acceptance by serious musicians.
Cursor for Music
This, to me, is the more interesting question. There are many companies making great efforts to accelerate slices of the music creation “inner loop” with AI—Splice, Neutone, Izotope, Ableton’s MIDI generation, Google Magenta—but no product has shifted the field the way Cursor seems to.
There are many reasons for this. I suspect this is in large part because programming long ago standardized on text as the de facto format for nearly all intermediate representations. Vim users know that basically every step of creating software can be done with just a keyboard—they won’t shut up about it. This text-centrism makes it easy for text models to interop with various parts of the software creation process.
Music production, on the other hand, has many disparate intermediate representations. DAWs require a lot of clicking around. Some of these are well-known by the Music ML field as the “symbolic representations”—MIDI and notated music, for example—but other forms of human aperture-guiding are less well-recognized by the field, like VST selection, parameter automation, loop sequencing, and arrangement.
On a social level, Cursor’s creators are its users—it’s software for software people. Software for music people is inevitably going to take more iterations to match the real-world workflows.
On an economic level, software is far more profitable than music. No music tool companies are nearly as profitable as the largest devtool companies, because only a tiny proportion of music tool companies’ customers see positive ROI from their purchase.
So What?
For all the pedantry, I think we land on a useful conceptual framework with literal implications. When considering the creative process as navigating to a desired point on the manifold, and AI tools as functions that give some degree of semantic controls in that navigation process, it opens up meaningful comparisons across domains. In this case, I think it highlights opportunities for the music tech community to learn from the devtools community, and keep working toward “Cursor for Music.”
Don’t get me wrong: some musicians will definitely still hate us. But I think it’s more likely that some will thank us.